還記得第一次使用手機上的「Hey, Siri」或是「Ok, Google」功能時的自己有多興奮嗎?在接下來幾天的文中,我會講解昨天提到的幾個自然語言處理主要課題。講解完每天的課題之後,我會在當天或隔天準備一份與該課題有關的實作,帶大家體驗這些課題可以如何應用。
前言所說的功能,或許現在的我們早就習以為常了,但卻不一定明白其背後的原理,因此在這裡我們就來簡單介紹一下吧!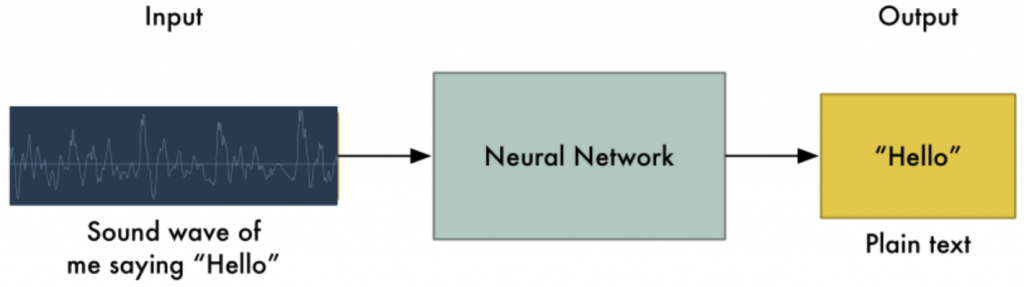
語音辨識的第一個步驟就是將我們說話時的音波根據頻率的高低起伏轉換成電腦讀得懂的數字,接著放到類神經網路根據那個時間段(每20毫秒)的音波來判斷這個字是a, b, c, ...的機率分別有多高,最後根據這些頻率的馬可夫鍊排列出最高機率的字。隨著語音辨識的進步,現在辨識字的正確率越來越高了,而且現在多數語音辨識的功能都不會只看單一個字,還是把它前後的字也列入考量,這會和我們之後所要提到的專題 -- 自然語言生成中的語言模型有關。
文字朗讀則反過來:首先將文字轉化成音素序列,接著將音素序列標上重要的資訊,例如起始時間、頻率變化等,最後進行語音合成。
小時候不論在學中文或英文時,我們常會需要知道一個詞的詞性到底什麼。學古文四十時,我們需要知道「故者不失其為故」的兩個「故」分別是什麼詞性;學英文時我們也需要知道「Will Will make this decision?」(威爾會做這個決定嗎?)中的兩個「Will」到底哪個是名詞,哪個是動詞。了解詞性對於人類來說,是明白一句話的關鍵,對於自然語言處理來說也是如此。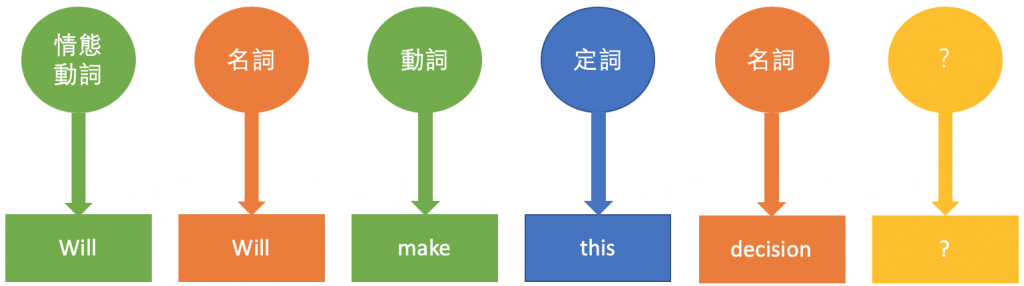
詞性標注對於許多自然語言處理的預步驟,這項任務所面臨的難題也正巧和我們的成長過程一樣,同樣一個字形,我們該如何給它標上正確的詞性呢?多數時候我們會用Hidden Markov Model及Viterbi演算法(一種動態規劃演算法)來完成這個任務,但還有一個更簡單且直觀的方法,就是從一個已經標註好詞性的文集中,記錄每一個字形是出現各種詞性的頻率,接著在標註的時候,每當看到那個字型,就標上那個頻率最高(最常見)的詞性。這個方法稱作Unigram Tagger,常會被用做詞性標註好壞的底線(Baseline)。
明天將會開始本系列的第一段實作,要來看看怎麼實際讓電腦替我們標註詞的詞性。

